Hadoop - Custom Partitioner implementation using wordcount.
Here is an simple implementation of partitioner class using standard word count example. In below word count example , integer values will be send to first reducer and text values will be send to second reducer using custom partitioner.
Sample Input to Program:
1 2 3 text sample file
3 2 4 timepass testing
text file sample 1
Sample Input to Program:
1 2 3 text sample file
3 2 4 timepass testing
text file sample 1
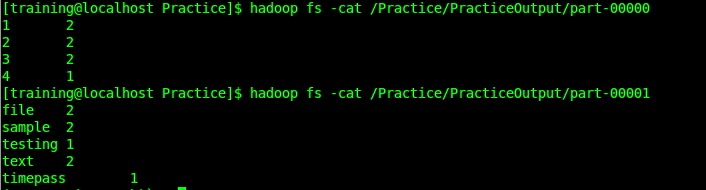
Expected Output:
part-00000
1 2
2 2
3 2
4 1
part-00001
file 2
sample 2
testing 1
text 2
timepass 1
Runner Class:
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class wc_runner {
public static void main(String[] args) throws IOException{
JobConf conf = new JobConf(wc_runner.class);
conf.setJobName("WordCount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setNumReduceTasks(2);
conf.setMapperClass(wc_mapper.class);
conf.setPartitionerClass( wc_partitioner.class);
conf.setReducerClass(wc_reducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf,new Path(args[0]));
FileOutputFormat.setOutputPath(conf,new Path(args[1]));
JobClient.runJob(conf);
}
}
Mapper Class:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class wc_mapper extends MapReduceBase implements Mapper<LongWritable,Text,Text,IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()){
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
Partitioner Class:
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.Partitioner;
public class wc_partitioner implements Partitioner{
@Override
public int getPartition(Object key, Object value, int arg2) {
// TODO Auto-generated method stub
if( isNumeric(key.toString()))
{
return 0;
}
else
{
return 1%arg2;
}
}
public static boolean isNumeric(String str)
{
try
{
double d = Double.parseDouble(str);
}
catch(NumberFormatException nfe)
{
return false;
}
return true;
}
@Override
public void configure(JobConf arg0) {
// TODO Auto-generated method stub
}
}
Reducer Class:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class wc_reducer extends MapReduceBase implements Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
int sum=0;
while (values.hasNext()) {
sum+=values.next().get();
}
output.collect(key,new IntWritable(sum));
}
}
Create a jar file and execute using following command:
hadoop jar WordCount.jar wc_runner /Practice/Input.txt /Practice/PracticeOutput
Here i have placed Input.txt into my HDFS directory. You give your own input and output path to run this command.


Comments
Post a Comment